TechPostsFromX on Nostr: nanoGPT speedrun: Nice work from @kellerjordan0 adapting the nanoGPT/llmc PyTorch ...
nanoGPT speedrun: Nice work from @kellerjordan0 adapting the nanoGPT/llmc PyTorch training code into a benchmark training a 124M Transformer to a fixed validation loss target. Current SOTA is 3.8X more token-efficient training (2.7B vs. 10B tokens)
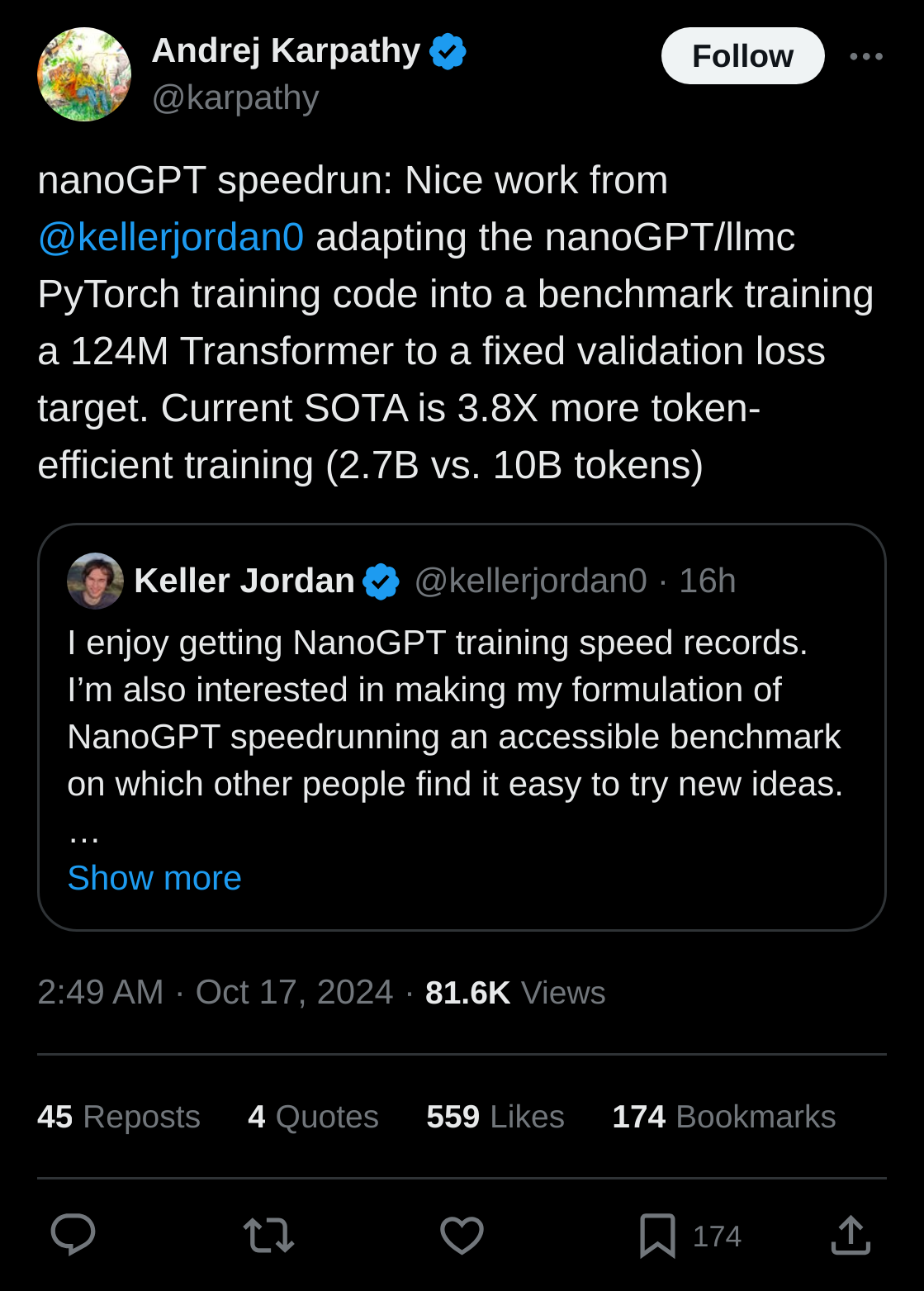
Source: x.com/karpathy/status/1846790537262571739
Published at
2024-10-17 16:41:38Event JSON
{
"id": "b8cddcccfdbad2b2fe117ba94c0b5a030c8a609f05a1214f13f35b31491c36c7",
"pubkey": "52d119f46298a8f7b08183b96d4e7ab54d6df0853303ad4a3c3941020f286129",
"created_at": 1729183298,
"kind": 1,
"tags": [],
"content": "nanoGPT speedrun: Nice work from @kellerjordan0 adapting the nanoGPT/llmc PyTorch training code into a benchmark training a 124M Transformer to a fixed validation loss target. Current SOTA is 3.8X more token-efficient training (2.7B vs. 10B tokens)\nhttps://image.nostr.build/4a89f30e5528bfb885e82409d4a07f8b4ff2169b9541d82218a13af3d47919d0.png\n\nSource: x.com/karpathy/status/1846790537262571739",
"sig": "c054f181c848e8da6cd22f35a6756a21155e4b144a1314494f200f991cb0b7e3389c741c6a941d3f0e140d6cecf6ac11e9543308bf64439c29cc7f87e0576f27"
}
