Event JSON
{
"id": "2cb499aa1a8b74678c815558574c2c914011859bcf1abbec07c10d3bb3c583f1",
"pubkey": "c98cd5eb63c6ea6b3832a507fa5416d8b5a1b3ea91ba1f57c472578debe10be3",
"created_at": 1717379020,
"kind": 1,
"tags": [
[
"t",
"research"
],
[
"t",
"llm"
],
[
"t",
"nlp"
],
[
"t",
"nlproc"
],
[
"t",
"papers"
],
[
"t",
"generativeAI"
],
[
"imeta",
"url https://cdn.masto.host/sigmoidsocial/media_attachments/files/112/550/151/388/240/494/original/9fb7a46d9d0b1ea4.png",
"m image/png"
],
[
"proxy",
"https://sigmoid.social/@BenjaminHan/112550151507428337",
"web"
],
[
"proxy",
"https://sigmoid.social/users/BenjaminHan/statuses/112550151507428337",
"activitypub"
],
[
"L",
"pink.momostr"
],
[
"l",
"pink.momostr.activitypub:https://sigmoid.social/users/BenjaminHan/statuses/112550151507428337",
"pink.momostr"
]
],
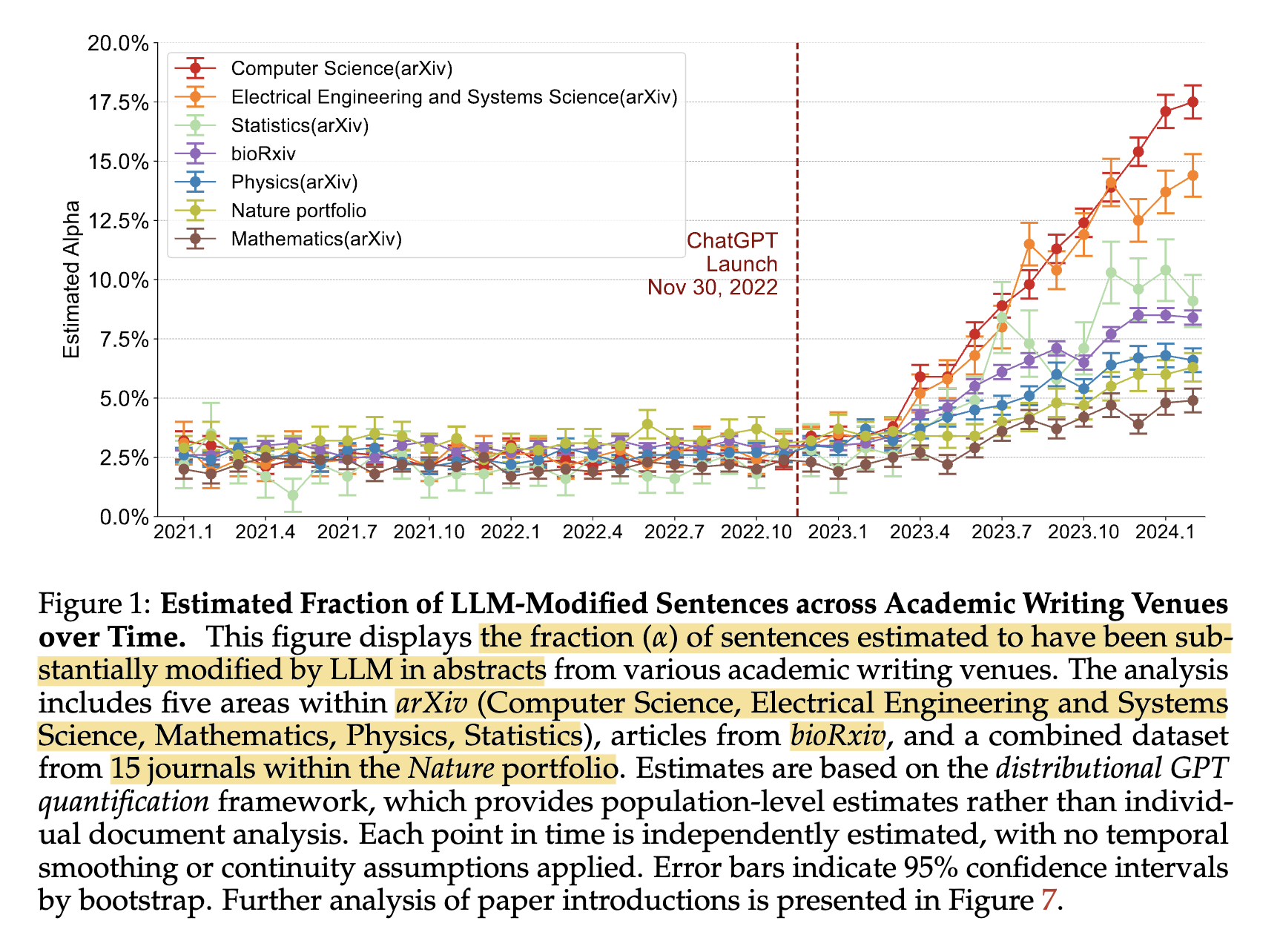
"content": "1/ \n\nWith #LLM applications more abundant, have researchers been using them to assist their writing? We know they have when writing peer reviews [1], but how about doing so in writing their published papers?\n\nLiang et al comes back to answer this question in [3]. They applied the same corpus-based methodology proposed in [2] on 950k papers published between 2020 to 2024, and the answer is a resounding YES, esp. in CS (up to 17.5%) (screenshot 1). \n\n#NLP #NLProc #research #Papers #GenerativeAI\nhttps://cdn.masto.host/sigmoidsocial/media_attachments/files/112/550/151/388/240/494/original/9fb7a46d9d0b1ea4.png\n",
"sig": "6619f937259c7640a5da9c90ea8789e7e0435aa1c0af22e9503b5550cf30720d7466c7a27bcddc3100151d54c4df20e751cee5dbe96e8882b20983f77c6753d9"
}