The dream of building this thing called a “web of trust,” a decentralized method for connecting our decentralized identities in a variety of ways for a variety of reasons, has been around for at least 3 decades, ever since Phil Zimmermann released Pretty Good Privacy in 1991. Since then, many attempts have been made to build something worthy of the hype; something genuinely decentralized and truly useful. Unfortunately, by many measures, our attempts have failed to live up to expectations. This failure is due, in part, to the lack of a clear picture of what exactly web of trust is, what exactly it should do, and how exactly we want it to work. In this essay I argue that lists will play a central role in helping us to wrap our heads around web of trust and to build a roadmap to turn this dream into a reality.
Why web of trust?
It helps to begin with the question: why should we care about this topic? What do we want our webs of trust to do for us?
facts and information
As a user, I need help understanding the world. On most topics, I am not an expert. On most topics, I don’t even know who the experts are! Finding the people and sources from which I can obtain trustworthy facts and information about the world is something that I want from my web of trust.
Could web of trust just give rise to nothing more than better echo chambers? Yes, web of trust can be used to build echo chambers, if that’s what you want. I’d argue, though, that it’s hard to build better echo chambers that what we already have. If that’s what you want, you don’t really need web of trust to do it. And there are many topics that are not controversial or political, about which we want nothing other than objective truth.
So: It may be said that the first thing we want from our webs of trust is facts and information.
digital tools of communication
But facts and information is not the only thing, and I would argue, not the main thing. I would argue that the main thing we need from our web of trust is help to manage the very tools that we use to communicate; the very rails upon which facts and information will reach us.
By digital tools of communication, I’m talking about protocols, like the nostr protocol; platforms, like the ones for most nostr clients, most of which are held in open source repositories. I’m also talking about libraries, schemas, ontologies, standards. Digital tools that most users may not comprehend, even in the slightest. But use them nonetheless. Even if programming is your thing, you’ll never know everything about all of the tools you’re using. So unless you are happy for the captains of big tech to be in charge of those tools for us, we need web of trust to select and to manage and to maintain these digital tools for us.
consider the spoken word
In English, what is this thing called?
✏️
The answer is, of course, a “pencil.” But now ask: who decided that’s what we call it? Who is in charge of the words we use to discuss that thing? Well, no one is in charge. We simply have all come to consensus – a loose one, but consensus nonetheless – that that’s what we call it. So the answer to the question: who decides? is simultaneously everyone and no one.
OK, wait a minute. Are we saying that there’s no World Wide Web Consortium committee that publishes a standard, with updates once a year, to dictate the words we use to discuss that thing? Are we saying there’s no pull request, somewhere, that somebody merged into some repository by whoever is maintaining the repo? The answer, of course, is yes. There is no single entity, anywhere, with the power, either in theory or in practice, to throw a monkey wrench, to bring to a grinding halt our ability to have a conversation about that thing.
The main thing we need from web of trust is to make all of those decentralized features of the spoken word to be features of our digital tools too. Our repositories, platforms, protocols, standards, and so on. Curation of all of these things things needs to be handled simultaneously by everyone and by no one. And there must be no monkey wrenches.
Sounds like a tall order. How the heck are we supposed to do that??!?
But wait, there’s more.
community
Our digital tools cannot be one size fits all.
As human beings we form naturally into communities. And sub communities. And sub sub communities. All the way down to communities of just two people. (I suppose there could even be a community of one or none, depending on how exactly we define [1] “community.”) Some communities overlap. Some don’t. Some are stable, in terms of membership and/or characteristics, over long periods of time. Some change rapidly.
Each and every community has its own distinctive, unique sets of needs. Its own reasons for existing as a community. Outsiders may or may not understand those needs and reasons. Outsiders may or may not approve. But guess what? As nice as it would be to experience universal understanding and approval, it is unwise to expect or demand those things from everyone, all the time.
We need our digital tools to be tailored to each community, individually. We need community-specific tools for all sorts of reasons, including (but not limited to) communication, and transaction, and coordinated action, plus any other class or category of in-group, entity-to-entity interaction that anyone might manage to conceptualize.
These tools must also be: sophisticated, powerful, versatile, and as complicated as they need to be for the task at hand. And yet, easy to use. And nimble, able to adapt to changing needs.
Imaging you are part of the French Resistance. Your local chapter has 10 people; or maybe 100. Or maybe no one has any idea how many people are in it, because no one has, or should have, a bird’s eye view of the whole community. A bug is discovered in the verifiable credential that you use to prove to one another that you’re part of this particular community. A hot fix is needed. And it’s needed now! Who is going to do it? Do you want to wait 6 months for some hypothetical United Nations Special Committee on Digital Credentials for Freedom Fighters to push a hot fix to the schema used to enforce the verifiable credential for your small and secretive group? Of course not. You want the fix to be done by someone whom you can trust. Someone inside the community. You need to select the people, who select the people, who select the people, who push the hot fix.
And you need to trust the solution, even if you don’t know who any of those people are.
This is why we need web of trust. Yes, it’s a tall order. But we have a path forward, and we think it’s a pretty good one.
Roadmap
So that’s why. We turn to the question: how?
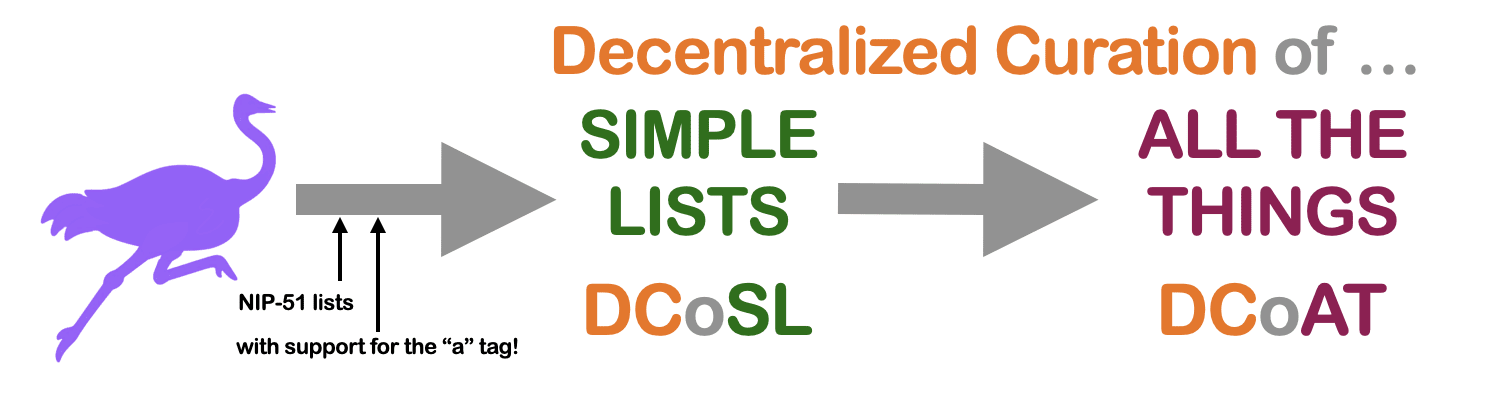
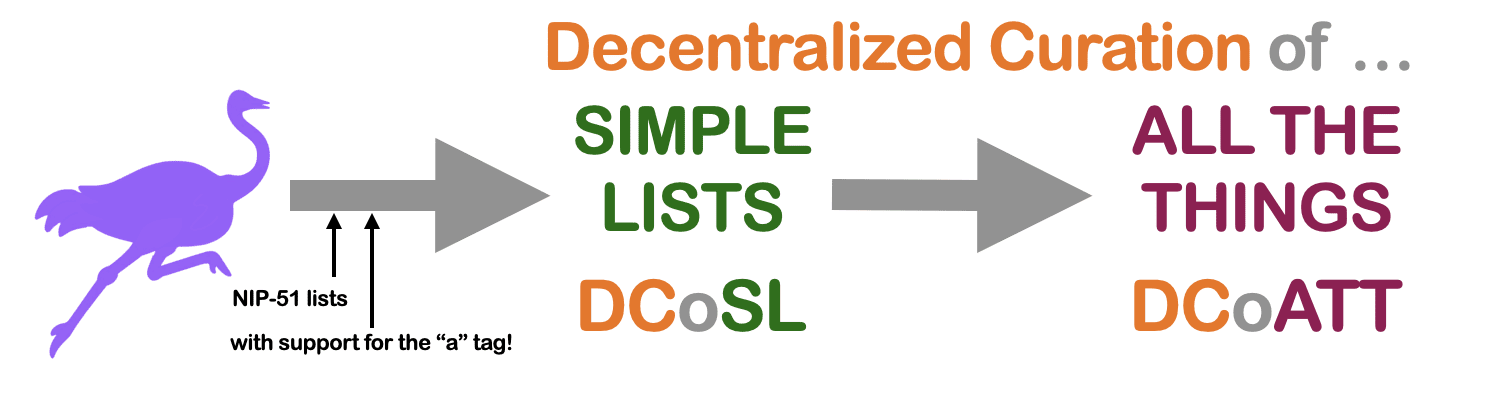
I’m going to propose a roadmap from where we are now (which, for the sake of discussion, I will identify as nostr in its current state) to where we want to be. But I’m going to change the name of the destination. Instead of calling it Web of Trust, I’m going to give it an acronym: DCoAT, which stands for: Decentralized Curation of All the Things.
And I’m going to argue that in order to wrap our heads around what we’re building, and how to build it, is that we introduce an intermediary goal: decentralized curation, not of all the things, but of the simplest thing that can be curated by one’s web of trust: a simple list.
So here’s our new roadmap:

This allows us to take this one goal that after over 3 decades has been resistant to all attempts even to define, let alone build, and to separate it out, conceptually, into two distinct questions that we can attack one at a time.
The first question is the harder one: what does decentralized curation mean? What do we want it to mean? Decentralization is a word that gets thrown around a lot. But it needs to be earned. Suppose I told you that I have a proof of concept, and I tell you it’s decentralized, and I go on to explain that it’s powered by a blockchain with some infathomably complex (but it still works – trust me!) algorithm, and it harnesses AI, and maybe quantum computing. All The Buzzwords. You would probably say: that’s not the solution we’re looking for. It would have monkey wrenches, even if they’re hidden, which means it would not be decentralized. That begs the question: what does a genuinely decentralized solution look like? What do we want it to look like? To that end, I have a proof of concept app that I have built, within an app called Pretty Good Apps [2], and I’ll give it an overview, below, so you can judge whether it’s truly worthy of the word: decentralized.
The second question is one that I think will fall into place more readily than one might think, given the magnitude of the overarching challenge at hand. The question is: assuming we’ve answered the first question to our satisfaction, how now do we go from Simple Lists to All The Things? I propose that it won’t be easy, but it will be tractable, which is all we need it to be. Because a simple list is a building block. If we have enough building blocks, we can build any thing that we want. We can build any arbitrarily complex piece of data. If we can curate a list, we can curate All The Things.
To give a small taste of what I mean, consider the fact that a graph can be represented by no more than two simple lists: one list for the nodes, and one list for the edges.
Imagine that the local chapter of Freedom Fighters is curating these two lists. And that the graph is used to represent a schema, and more precisely, the schema in question is the Verifiable Credential for our local branch that I mentioned earlier. That means we can push the hot fix. Immediately. And just like that, the war is won.
DCoSL: Proof of Concept
But before we win the war, we need curation of a simple list, and it needs to be genuinely decentralized. For starters, we need a proof of concept that we can all point our fingers at and say: this is truly decentralized, in the ways that matter. This is DCoSL.
Here is a screenshot from what is effectively my own private, personal desktop nostr app. I call it Pretty Good Apps, in honor of Zimmermann’s Pretty Good Privacy. It’s open source and the repo can be found here, on my GitHub account.
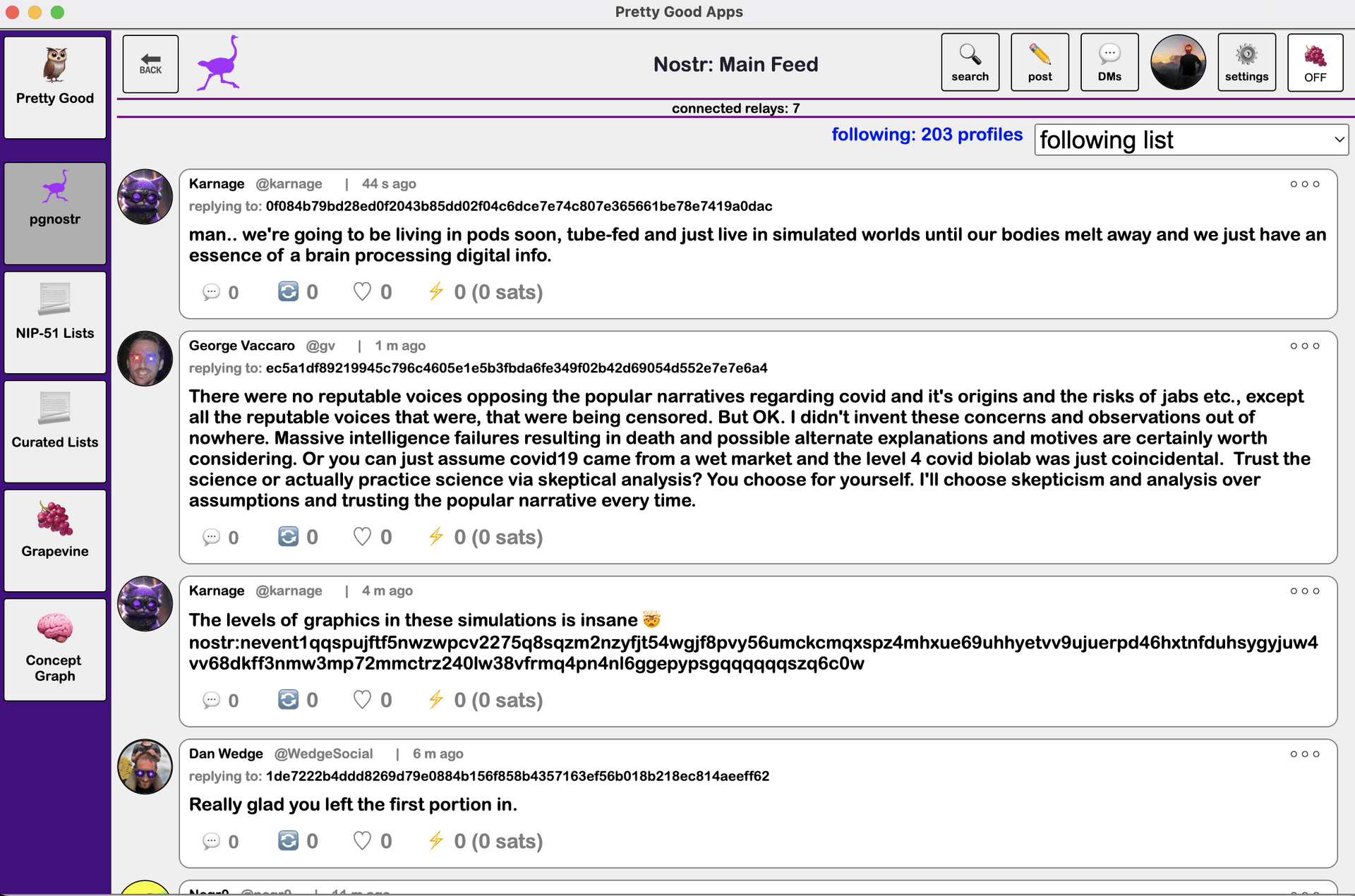
The reason I built this was to be my own personal playground, a tool I could use to flesh out these ideas on the pathway that I am describing in this essay. To clarify them in my own mind. To make them concrete. And so one of the apps within Pretty Good Apps is something I am calling Curated Lists. This is my proof of concept that DCoSL exists. Here is a screenshot.
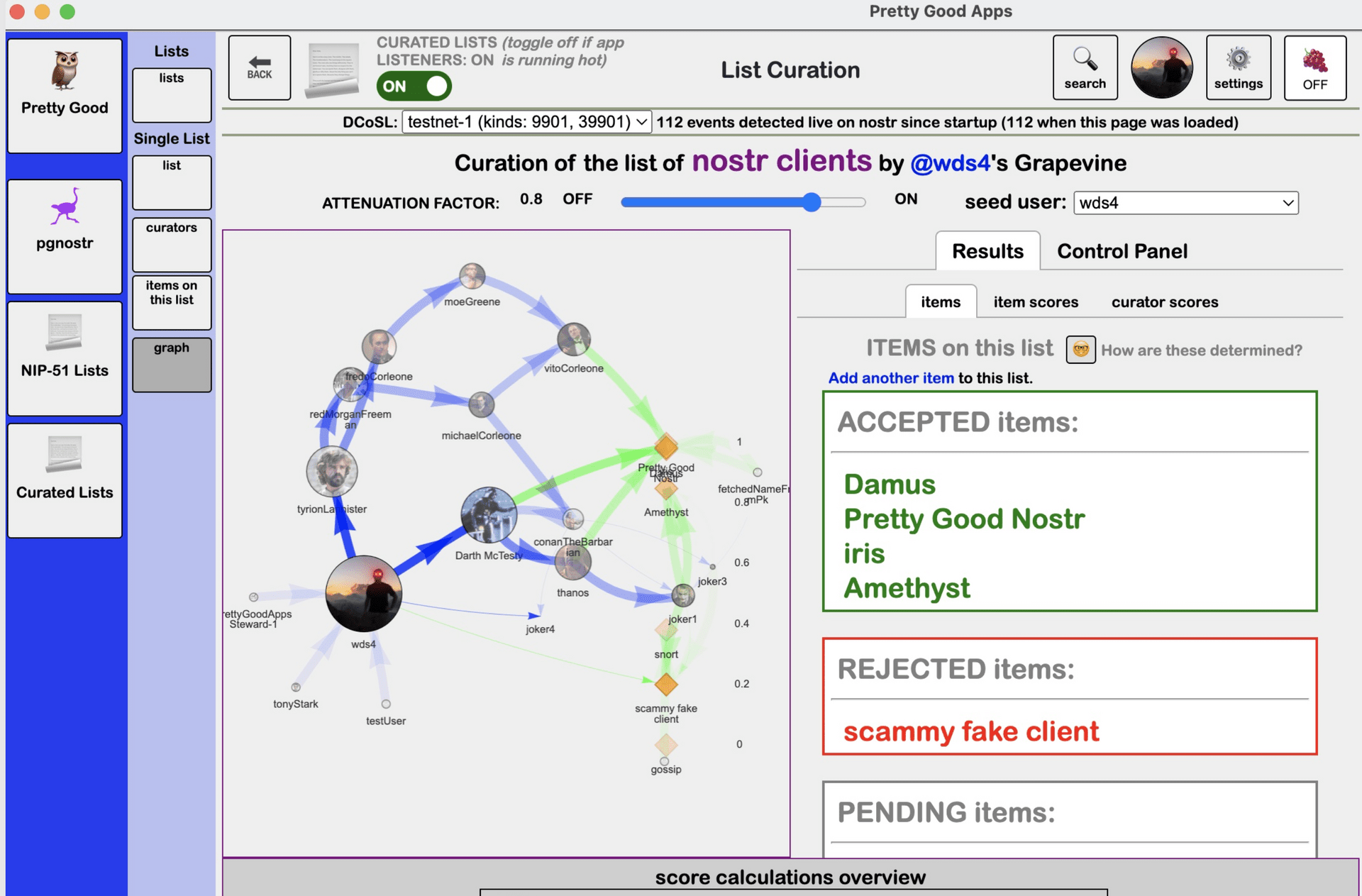
I am not going to go through everything that is happening in this screenshot. But I am going to give you the highlights.
Suppose I want to curate a list of nostr clients. In the absence of my app, using the current nostr protocol, and in particular NIP-51, you can go to a site like JeffG’s listr, and you can create that list. You can give it a name. You can add items to the list (as plain text, using the “t” tag). You can take items off the list. You can wrap up the list (list title plus items on the list) into an event, probably of kind: 30001 for this example, and publish it to nostr. If you want to update the list, you can do that too (because NIP-51 harnesses the magic of replaceable events).
But what if you come to believe that there are too many nostr clients for you to keep track of all of them by yourself? You want to select other people to manage the list. But guess what? You don’t even know who the knowledgeable people are on this topic. So you want your web of trust to find them for you too.
Nostr, as things currently stand, does not allow you to do that [3]. But these things can be done in my app. Using the DCoSL protocol, users can make a new list with a title like “nostr devs” plus a description, and that list (name and description, without specification of any items) is wrapped into an event (using kind: 9901 which I am using for DCoSL testnet) and stored in nostr. Anyone can make use of this list. Anyone can propose items to this list, each one of which is stored as its own event in nostr. Users can endorse other users as being trusted (or not trusted) to curate this list, and users can endorse proposed items as belonging (or not belonging) to that list.
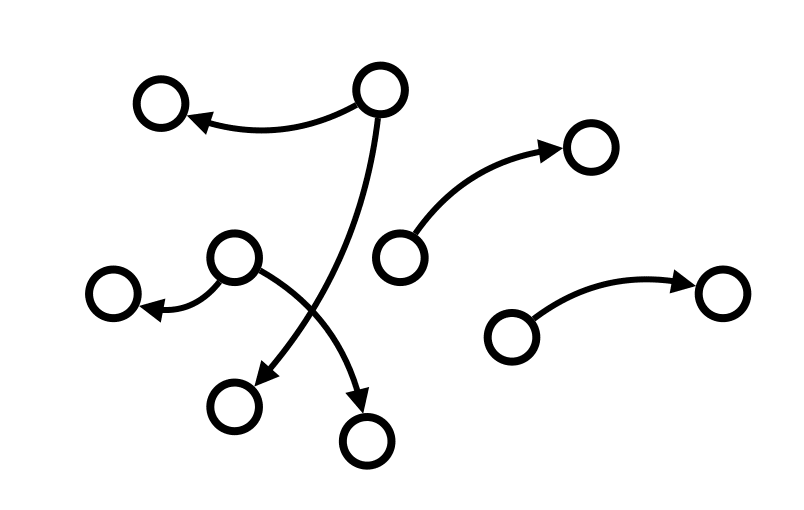
I built this proof of concept as my proposed answer to the question: what does decentralized curation of a list look like? I propose it looks like this:
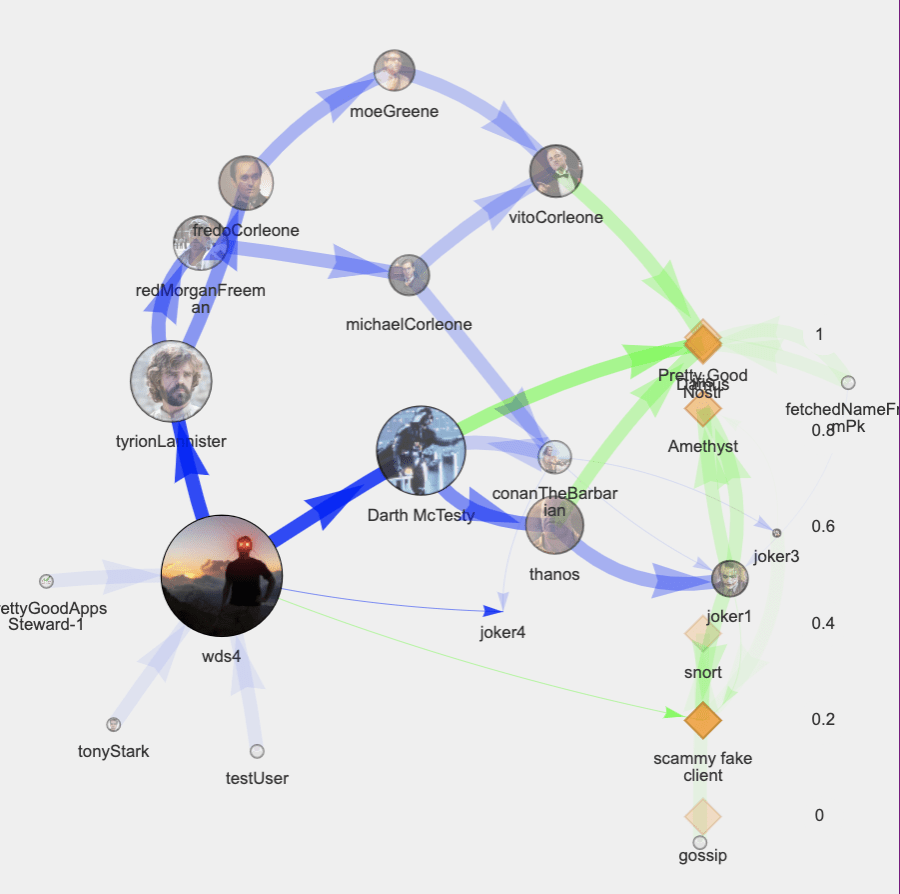
In the image above, the big circle is me. At the center of my web of trust. And each of the arrows mean that I am selecting the people (circles), who select the people, who select (or sometimes veto) the people, and so on – I may not even know how many iterations; but ultimately, my web selects the people who select the items (diamonds) that belong (or don’t belong) on this particular list.
So this is the result that my web of trust provides to me:
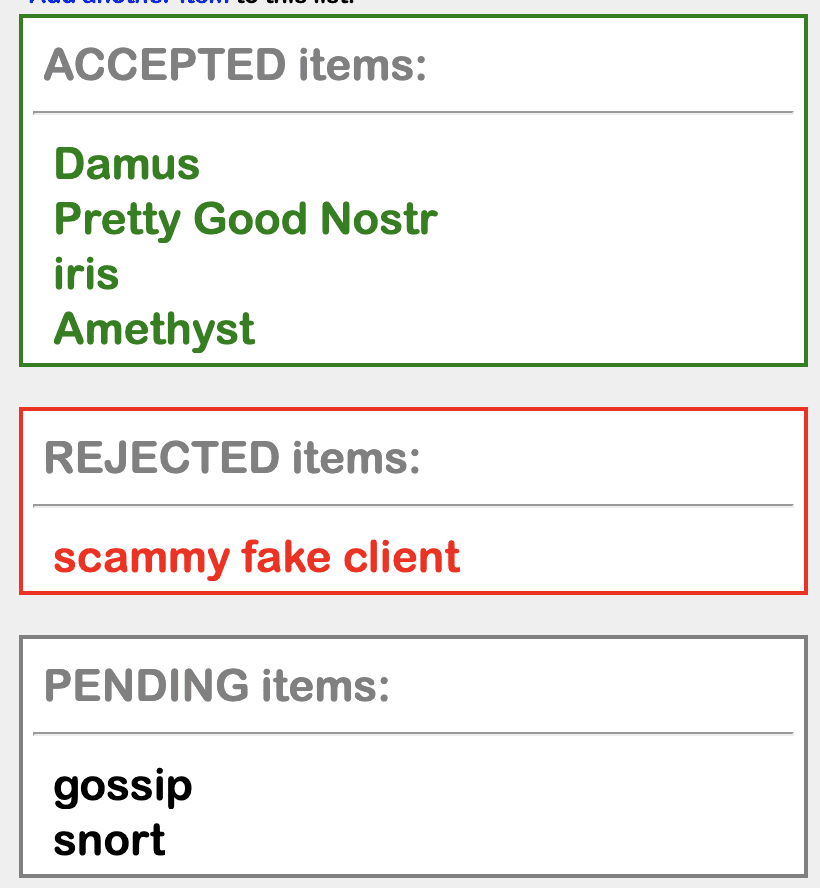
Who decided that Amethyst belongs on the list? No one. Everyone. Who decides this other item, “scammy fake client,” gets removed from the list? Everyone, and no one. If there is a single point of failure, it is me, because I’m always at the center of my web of trust. But the more important this question gets, the more people chime in, the more decentralized it becomes, and the harder it gets for anyone to toss in a monkey wrench.
And importantly, although it may not be immediately evident in this brief overview, it is NOT necessary for me or anyone to have a complete bird’s eye view of the entire web. Any given arrow in the above example is essentially a firsthand report. But does it have to be firsthand? According to how the proof of concept calculations are done, each arrow could represent a summary statement, a distillation of information from that user’s web of trust. It would be as if someone were to tell you: “That product is really good and I know that because I used it. Umm, errr, wait, I didn’t use it myself, I’m just telling you what my peeps told me.” You may or may not even know whether it’s firsthand or not. Which means entire portions of the web can be hidden from me. I don’t have to see the entire web for this method to work. Plausible deniability can be built in quite naturally as a feature, if you want it.
There are a lot of calculations that are happening under the hood that I will not review here. For example, the size of each circle indicates the amount of influence that particular person has in this particular context. The complexity of this method builds up, but not forever. It’s a tractable problem.
Current and future efforts
Right now my main goal is to present this roadmap to the world. If it makes sense, we will need a community effort, a labor of love, to turn the roadmap into reality. If it does not make sense, I look forward to feedback to tell me what I am either missing or perhaps just not explaining well.
I recently made my first hire, Anton Strickland (@kinjo), to begin the process of rebuilding the lists features of Pretty Good Apps as a web app, so that people in the community will have something to play with. Hopefully, the community will agree that this proof of concept does in fact constitute decentralized curation, that it has earned those words. Or if you don’t, perhaps you can teach me why! But if you agree, then I would love to see this method, or a variation of it, incorporated into a variety of clients, for a variety of applications.
In addition, I am in the process of writing up a protocol for DCoSL. Like nostr, which is built out of NIPs, this procotol is built out of DIPs. It is technically independent of the nostr protocol, but interfaces quite naturally with it. One section of this protocol, called the grapevine, is dedicated to the method you see above for curating the list of nostr clients. There is another section, called the concept graph, dedicated to the method of converting DCoSL to DCoAT, of taking lists and building data structures of arbitrary complexity, amenable to curation by the grapevine. In companion articles, I will go into detail about these two protocols and their corresponding apps. Be forewarned: as of the time of writing, the repositories for these protocols are far from complete. Some items are stubs, most will need revision, and many items are currently lacking.
I have been building these protocols and apps, but I’m going to need community help to build them out sufficiently for general usage. My hope is that this will become a community effort. And at some point, once these apps are sufficiently built out, you will be able to use them so that your web of trust will take over the task of managing these two protocols, and these two apps. And then our work will be done.
In the meantime, I would encourage all devs to consider incorporating lists using NIP-51 to their clients; and after that, to add “a” tag support to NIP-51, so that users can select lists by other users and import the items from those lists to their own. That’s all already in the nostr protocol. There’s nothing controversial about NIP-51 and its use of the “a” tag that I know of, based on brief conversations I’ve had with Rockstar and elsat and others at Nostrville; but of course, please tell me if I’m missing anything.
notes
[1] We will argue elsewhere that the shared tools of communication and interaction, digital or otherwise, are precisely how we separate one community from another. *Communities are defined by the shared cognitive frameworks that they use to interact as individuals.*
[2] Everyone is certainly welcome to play around with Pretty Good Apps and Plex, but be forewarned: they will break on you and as of the time of this writing are simply not yet ready for widespread usage.
[3] This is not quite true. Under NIP-51, using the “a” tag, I can decide that I want to import items from other people’s lists. I know @JeffG has this on the roadmap for listr, but I don’t know of any client out in the wild that provides a tag support to NIP-51 lists, with the exception of the NIP-51 app section of my own Pretty Good Apps. I encourage all devs to provide “a” tag support to NIP-51 lists in their clients, because it will be a strong step along the roadmap that I am advocating. More on NIP-51 and the “a” tag in a different article.